
Connected world, Cloud and Analytics
When we talk about connected things, lot of development is going on across all industry segments. We witnessed quite a few product launch announcements last year in this area. Still I feel there are a lot of challenges for its implementation, which includes remote connectivity, device management, network protocol standards, energy consumption, privacy/security and many others. Maybe this is the only reason why we are not witnessing large number of connected devices in our day to day lives, though the talks of IoT has been around us for more than a few years now. But that is not the case for industry usage of IoT. Industry is investing heavily on IoT and many implementations are already on production, helping real time operations, cost optimizations and resource utilizations. Please check out this video for further details on how Microsoft Azure IoT helps industry.
The evolution of public cloud will help to boost connected devices and its applications. It will not solve basic problem of Internet availability to things but will definitely solve the problem of connectivity and will help to process data easily. End to end solution for IoT applications with Amazon Web Services (AWS) have been implemented before the release of AWS IoT service launch. Here, architecture differences between before and after AWS IoT launch will be discussed to provide some more insights on how to leverage this new service for applications that covers data mining and analytics field.
Before AWS IoT service:
Below is the architecture in which sensor nodes connect to AWS Kinesis and sends sensor data.

Conclusion: After this we have multiple options to read data from AWS Kinesis stream. We can use Apache Storm for real time streaming analytics. Sample of Kinesis Storm spout is available here. To display real time data on dashboard, Kibana was used and Elasticsearch reads Kinesis stream and processed data is used by Kibana. But as AWS keeps updating its services with new features, it now provides Amazon Elasticsearch service out of the box. For more detail please check out this blog by Jeff Barr.
We can also use AWS Elastic MapReduce and process Kinesis stream with some MapReduce task. Storing data to DynamoDB or to other services is also possible.
After AWS IoT service:
There are many fixes needed in first part of above architecture. For example we have to manually manage all the components that are connected to network. Also to send data to specific AWS service (Kinesis in our case), AWS api keys with specific roles need to be present inside things/device. For all of that AWS IoT provides excellent solution. With that we can manage things/devices with all the features of AWS IAM which also includes certificate provisioning for things/devices. We can also revoke certificate associated with any node at any time.
Below is the architecture after using AWS IoT service:
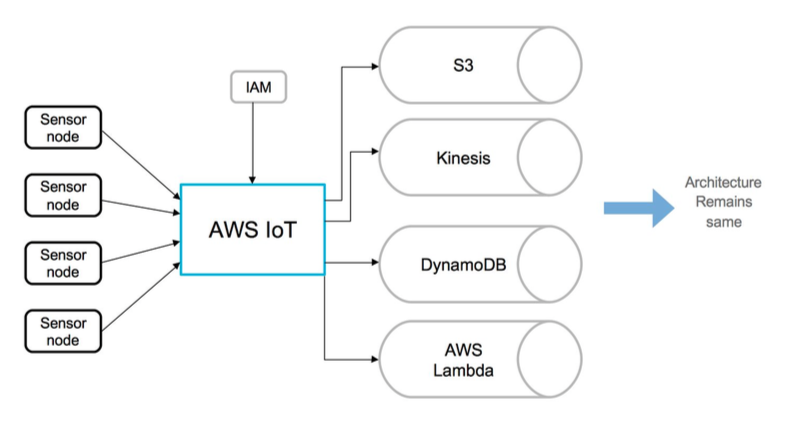
With Rules Engine of AWS IoT, we can route messages to different AWS services. It also provides much needed support for MQTT protocol. Some of the noticeable feature of this service includes Device Shadow and Device sdks. The remaining part of the architecture will remain same for some application of data analytics and visualization which includes Storm, Elasticsearch and other related methods. But with AWS IoT, we now can also talk to devices which enable us to design wide number of real time applications.
The ultimate goal will be to use historic data generated and find some pattern out of it that will drive some key decisions.
Conclusion:
With reduced hardware cost and availability of excellent cloud services, there is immense opportunity in various applications ranging from factory automation, healthcare, logistic & warehouse management, device/things remote monitoring to home automation.
By : Pushparaj Zala
Good article Pushparaj, the AWS Elastic/Kinesis and DynamoDb arch sounds interesting…
Cheers
Deepak
Pushparaj, thanks for the article and it’s really informative.
I would like to know your views on the following:-
– As you are aware the ElasticSearch is built upon Lucene which creates and maintains the index files on the disk. What is the fall back mechanism if the index file gets corrupted at the run time for some reason in non-clustered environment ?
– How about having ElasticSearch on Clusters ? Do we have any specific challenges ?
Good point Nataraj,
Corruption is always issue. I think Lucene comes with a tool to fix corrupted indices. But not really sure if it’s implemented in Elasticsearch. I found this issue – https://github.com/elastic/elasticsearch/issues/8708 which is tagged for v2.2.0, which you can look into it.
For corrupt shards we can always reindex the delta information from snapshot(but we need to have snapshot for single node cluster otherwise replica of node for cluster)
I haven’t really used elasticsearch at higher scale but ideally I prefer to have dedicated master nodes and for correct sizing we should do some load testing until we get combination well. Actually getting up and running elasticsearch is easy but creating efficient cluster(& running it) takes the most.