Don’t be afraid of the Storm (Part 1)
This is the first part of the series on learning Apache Storm. This includes introduction and will include examples in next parts
When I first heard that I have to build a platform which can handle a stream of data coming in faster than a Ferrari , is guaranteed to scale and should be modular enough that one can increase the nodes of a particular node which is feeling most of the heat, I began to feel heat around my forehead. But fortunately for me, I came to know the answer easily (but don’t tell my boss ? ).
Apache Storm
It is a distributed real-time big data-processing system. Storm is designed to process vast amount of data in a fault-tolerant and horizontally scalable method.
So basically it is designed to make our life easier by providing tools for handling the stream of data and scaling while hiding the implementation.
What does it mean for us?
- We won’t have anxiety issues about scaling
- our BP will be stable because of fault tolerant system
- we will be calm even with huge amount of streaming data
and last but not the least “we can focus on our work ?”
So how does it work?
Apache Storm makes use of the concept of directed acyclic graph(DAG) with spouts and bolts acts as nodes of the graph. Each edge represents data stream from one node to another. Spout and Bolt are known as Task and this whole graph is known as Topology in Storm.
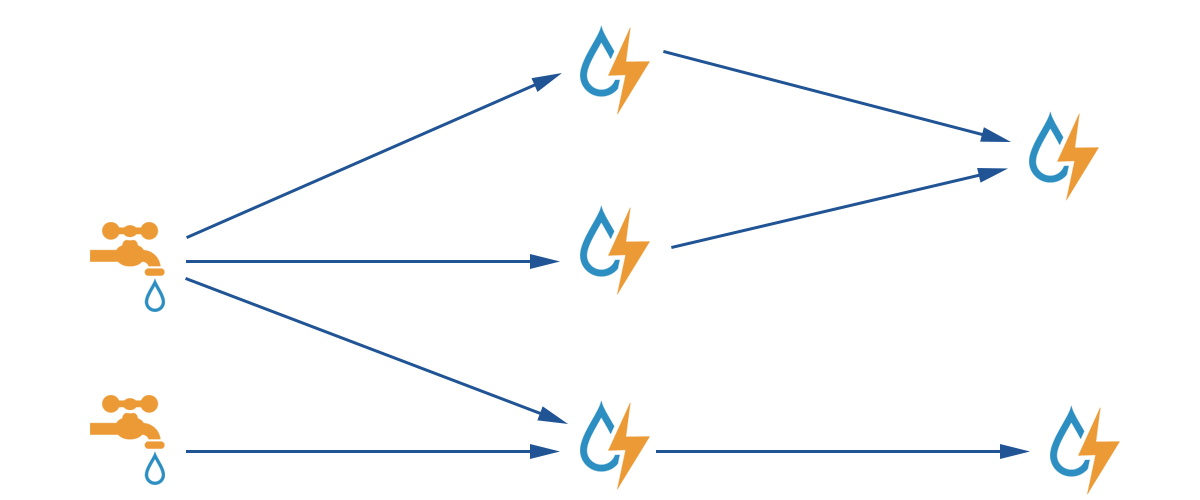
Spout acts as a provider. It receives data from the external source and passes it forward to bolts. Spouts do not contain much business logic (mostly no logic at all).
Bolt, on the other hand, contains business logic. But you don’t put whole logic in one bolt(that would violate the whole concept). They should perform a specific task and forward the data to another bolt for next task (if necessary else forward it to the external source).
By making spout and bolt stateless, we make full use of storm’s concept of “parallelism hint“. This property tells storm, how many instances of a particular node (spout or bolt) should be running simultaneously. Each node can have its own value and can be set at runtime.
Nodes talk to each other using Stream. The stream is the core abstraction in Storm. A stream is an unbounded sequence of tuples that is processed and created in parallel in a distributed fashion. Tuple can contain Integer, String, Byte array or custom serializable classes.
I will explain how these things work with an example in next part of the series. For now, let’s talk about the Storm architecture.
Apache Storm Architecture
Storm by default work like a cluster and it mainly consists of two things :
- nimbus: master node
- supervisor: worker node
Nimbus acts as an orchestrator. We submit topology to nimbus and it breaks down the topology to tasks. After that, it figures out which all worker nodes are free and distributes the task between them. Those worker nodes don’t have to be on the same server.
Supervisor, on the other hand, acts as a worker node. It manages workers running on the same server. It gets the tasks from nimbus and distributes it to workers. Each worker has its own process.
Worker won’t execute those tasks by itself, they spawn threads (known as executors) and each thread executes its own task.
Storm can contain multiple nimbus instances but only one will be active at a time. If one goes down, other takes its place. This is not the same for supervisor, all supervisors remain active and get their task from nimbus.
It uses Zookeeper to help the supervisor to interact with the nimbus. Zookeeper is responsible for maintaining the state of nimbus and supervisor. Since the state is available in ZooKeeper, a failed nimbus can be restarted and made to work from where it left.
Here’s the link for a step by step guide for creating storm cluster.
That’s all about the introduction, in the next part we will get our hands dirty and work on an example.
By,
Tiwan Punit
www.coviam.com
2 thoughts on “Don’t be afraid of the Storm (Part 1)”