System Design lessons learned from Apache Kafka
This article focuses on various design concepts:
- Horizontal scaling
- Vertical scaling
- Data sharding
- Availability
- Fault tolerance
- Consistency
- Cap theorem, etc.
Whenever you are asked to solve a design problem you need to come up with a solution that has to satisfy many requirements. Eg: High availability, consistency, scale up to given user base, etc.
There is no such thing as the best design. We always design a system based on multiple factors that are critical to us. Eg: One might want to have a system built that can maintain consistency or availability.
You must have heard about CAP theorem, so let’s talk about that. In the modern distributed system you can achieve only two among Consistency, Availability and Partition tolerance. As you always need to have partition tolerance in modern distributed systems, you have to choose only one between availability and consistency. So Cassandra, CouchDB follow P-A, and hbase, cache follow P-C. I would recommend you to read a case study of these using CAP theorem. If you want to build a system with high availability, it can be done by running multiple replicas. If scalability is a concern, there are two ways to do it:
- Vertical scaling, where you add resources to a single node. Eg: CPU, memory, etc. But you cannot add more resources after a certain limit. So this is not the greatest way to scale.
- Horizontal scaling, where you have load balance running at the front and multiple nodes running at the back. There are multiple ways to distribute load here. So if an application is getting huge traffic, it can easily be scaled adding more nodes horizontally. There are no restrictions in this approach.
Let’s talk about data store side. While designing a system you always have multiple choices in terms of choosing data store, eg: postgres, mongodb, cassandra, mysql etc. As we discussed, this also depends on the given system requirement, eg: high write, high reads, schema conformity, multiple entities with joins vs single self-contained document etc. There are multiple factors which need to be considered while choosing a data store.
If you are designing a social networking site or a blogging system, where users can post and others can comment, like etc., or if you choose any rational database, then you will have to perform multiple joins to get the required data. So, designing a self-contained document would help here. There are multiple models in DB design, let’s discuss two models:
- Master-slave(multiple) (like MongoDB, etc.)
This allows you to write on the primary node and reads can be performed on remaining nodes. So any updates writes gets executed on master/primary node, and other nodes follow transaction/operation log and do the same operation. This way other nodes achieve synchronisation to master. - Master-multi-slave (like cassandra, etc.)
This allows you to write/update on 2 or more nodes and read from remaining nodes. So it helps in getting faster write to the system. At any point, if the primary node goes down, there is an election algorithm that starts an election and chooses a primary node so that DB keeps running properly without fail.
There is a concept called data sharding in the database. Let’s say, you need to design a data store that can store a huge amount of data. If you do it with single collection/table on single node, it won’t perform well. In such scenarios, you need to split the data, and need to store it in multiple nodes. There are multiple ways to shard data. I would recommend you to go through various sharding strategies, eg- hashing, lookup tables, routing etc.
Now, let’s talk about designing a distributed messaging queue that can allow faster write, high availability and fault tolerance. It should be able to perform well where multiple publishers write to it and need to process these events faster. So, the overall throughput needs to be better.
Let’s take this as a challenge and try to come up with a basic solution before you read further.
You can think of having a queue data structure on single node. There are two points to it: the first one, current_read, you are reading messages from this, and the second one, where you are performing write operation.
Now think of multiple publisher publishing messages, so it would not be able to write faster as it would get locked when one thread writes to it. This will be extremely slow in terms of processing incoming event streams, and if you can’t do faster write you can’t do faster reads. So, there’s a need to think of something else. What if you have multiple queues on a single node and you are sending events to these queues simultaneously, and would not get blocked here. Let’s say, you need to process millions of events very faster, you can’t do it on single node. So we can setup these queues on multiple nodes, and allow write simultaneously. And can write to these in round-robin/hash based strategy, so single queue node won’t be overloaded. If you want to maintain availability, you need to run replicas as well. And if any node goes down, it should be able to elect new leader out of given replica nodes. Here, writes should happen to leader queue node and replicas should be syncing to leader. So, you are good to go in terms of faster write, availability, fault tolerance. Now if you run multiple consumers, can process these individual queue nodes and process events to get better throughput, this solution would be somewhere close to kafka.
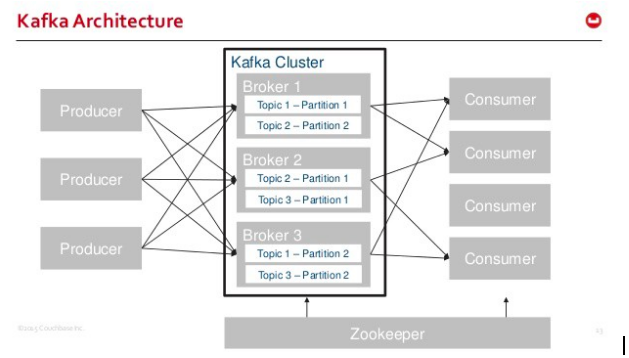
Source: Cloudurable
Before we try and understand kafka, let’s understand a few keywords, like- topic, partition, broker, cluster, consumer group.
Topic : You can have multiple topics in a given application. Eg: In e-commerce applications, ‘order’ events for order data, ‘active products’ events for new active products, ‘out of stock’ events for the products that are not available. So we can have 3 different queues/topics here to process the given data.
Partition : As discussed earlier, an incoming stream can be huge. We must split it and store it on multiple nodes. Kafka allows us to setup multiple partitions for given topics so that concurrent write happens faster and also runs replicas for each partition. There is one leader and the remaining are slaves. Kafka writes incoming events to the leader partition and the other partitions sync with the leader. Once it gets completed, kafka sends an acknowledgement to the publisher. The publisher follows the round robin strategy to sends events to various partition by fault. You can also configure hase key based distribution, where an event with given hashkey always goes to the same partition. We get the events ordering at the partition-level and not at the topic-level.
Broker : Broker is a kafka server that can have multiple partitions running on it. Kafka also runs replicas of broker so that if a broker goes down, kafka still keeps running without any failure of data.
Cluster : Kafka runs multiple brokers in kafka cluster.
Consumer group : There can be multiple consumers in a given consumer group and they would be reading from multiple partitions for a given topic. But all the given events get processed by one consumer in the same consumer group whereas if we have multiple consumer groups configured for a given topic, then each event gets processed by both consumer groups. This allows us to achieve many critical use cases in real time application, eg: Let’s say you have order streams of the products that we get from a customer, now we can run two consumer groups for this- the first one will process these orders, and the second one does analytics on order data. You need to make sure that kafka runs with multiple partitions to achieve better parallelism.
So that’s how kafka is one of the best distributed messaging application. And I truly feel if you try to understand kafka, you can understand many basic design concepts. Thank you so much for reading my post. I would keep writing about system design, scalability, event driven architecture and microservices in future.
Also published on Medium.