
Text Summarization Best Explained – Part 1
TEXT SUMMARIZATION
This article talks about the implementation of the concepts described in the blog Get a handle on deep learning with Attention.
What is Summarization?
Summarization means to sum up the main points of any source of information. It can be done through text, graph, images, videos, etc.
Text Summarization is the process of shortening a text document to create a summary of the major points of the original document. The document can be an article, a paragraph, a lengthy document etc.

There are two approaches to automatic Text Summarization:
- Extraction
- Abstraction
-
Extraction
It involves pulling key phrases from the source document and combining them to make a summary.
Example : Joseph and Mary rode on a donkey to attend the annual event in Jerusalem. In the city, Mary gave birth to a child named Jesus.
Extractive summary : Joseph and Mary attend event Jerusalem. Mary birth Jesus.
-
Abstraction
Abstractive summarization means to generate a summary of a document.
Example : novell inc. chief executive officer eric schmidt has been named chairman of the internet search-engine company google.
Abstractive summary : novell chief executive named eric schmidt to head internet company.
In the example above, the word ‘head’ is not a part of the original article. This is because in abstractive summarization words are generated and not pulled out of the article. Also, it overcomes the grammatical inconsistencies that we see in the extraction method.
This blog talks about the abstractive way of summarising a text document. The Encoder-Decoder architecture with attention is popular for a suite of natural language processing problems that generate variable length output sequences, such as text summarization.
How to summarize a text document using Attentional Encoder Decoder Recurrent Neural Networks ?
Deep learning models that use sequence to sequence models with attention mechanism have been successful in many problems like machine translation (MT). These models are trained on large amounts of input and expected output sequences, and are then able to generate output sequences for the inputs never before presented to the model during training. We can use the same model for text summarization as well. This model can be called as Attention-Based Summarization.
The summarization task can be defined as:
Given an input sentence, the goal is to produce a condensed summary of the input. Let the input consist of a sequence of M words x1, . . . , xM coming from a fixed vocabulary V of size |V| = V . A summarizer takes x as input and outputs a shortened sentence y of length N < M.We will assume that the words in the summary also come from the same vocabulary V and that the output is a sequence y1, . . . , yN .
Fig 1 : Encoder Decoder Neural Network
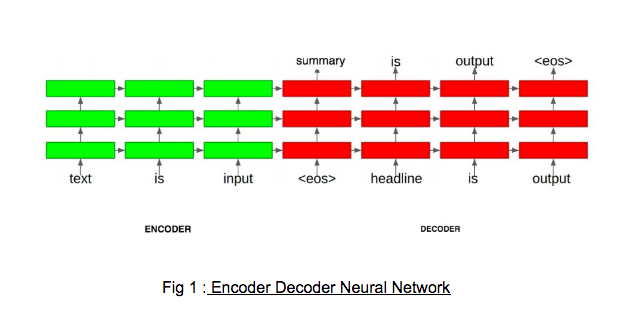
- Encoder The encoder is fed input text one word at a time. Each word is first passed through an embedding layer that transforms the word into a distributed representation. A bidirectional RNN can be used as it consists of forward and backward RNN’s. The forward RNN reads the input sequence as it is ordered (from x1 to xT ) and calculates a sequence of forward hidden states. The backward RNN reads the sequence in the reverse order (from xT to x1), resulting in a sequence of backward hidden states.
- Attention Fig 2 : Attention Mechanism in Encoder Decoder
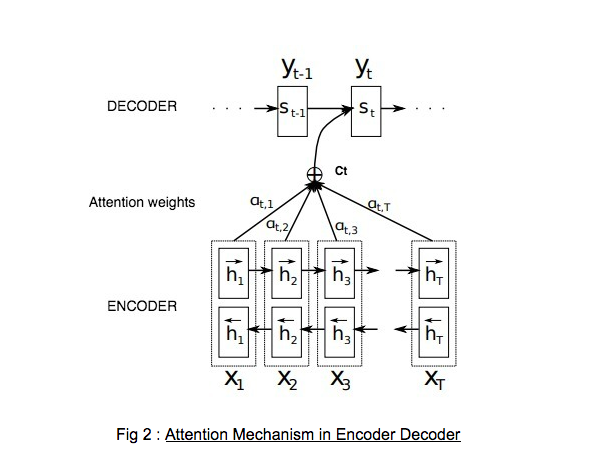
Attention is a mechanism that helps the network remember certain aspects of the input better that are more important. The attention mechanism is used when generating each word in the decoder. For each output word the attention mechanism computes a weight over each of the input words that determines how much attention should be paid to that input word. The weights sum up to 1, and are used to compute a weighted average of the hidden layers generated after processing each of the input words. This weighted average is referred as the context vector. The context vector is used by the decoder to generate output words.In Fig 2, we can see that x1….xT are the input words. h1….hT are the hidden encoded representations of the input words. αt,1 is the attention probability that the target word yt is aligned to, or translated from, a source word x1. Then, the t-th context vector Ct is the expected context vector over all the input words with probabilities αtj. The context vector Ct along with the previous output hidden state St-1 are used in deciding the next state St and generating yt.
- Decoder The decoder takes input as the hidden layers generated after feeding in the last word of the input text to the encoder. The decoder generates each of the words of the output summary using a softmax layer and the attention mechanism as described above. After generating each word, that same word is fed in as input while generating the next word. This is known as greedy search algorithm where the most likely word at each step in the output sequence gets selected. But it is not recommended to use greedy search. The reason can be seen in the example below.
For example in a greedy decoder :Correct output : I am visiting NY this year end.
Greedy decoder output : I am going to be visiting NY this year end.
In the example above, we can see the correct output that should be generated by the decoder. But if greedy decoder is used then the probability of “going” after “i am” is more.
Therefore, this approach is faster but the quality of the final output sequences may be far from optimal.
A more optimal search algorithm that can be used is beam search. Instead of greedily choosing the most likely next step as the sequence is constructed, the beam search expands all possible next steps and keeps the k most likely, where k is a user-specified parameter called as beam width and controls the number of beams or parallel searches through the sequence of probabilities.
How does Beam search work?
Step 1 : Let the beam width be k. The decoder network outputs softmax probabilities over the vocabulary V. According to beam search algo, top k most likely words are kept in the memory to be used later in the model. Let the k most likely words be v1, v2,… vk. All these words are a candidate for y1 ( output word).
Step 2 : In this step, we try to predict the next probable word if y1 has already occurred. We try to find the probability of y2 i.e P (y2 | x, y1) .
Our aim is to maximize the probability of y1 and y2 occurring together.
P (y1, y2 | x) = P (y1 | x) * P (y2 | x, y1)
Here x = v1, v2 …… vn (all words in the vocabulary)
k most likely pairs are going to be selected for further steps.
Step 3 : In this step we try to predict the third probable word’s probability
i.e P(y3 | x, y1, y2). Here the aim is to maximize the probability of y1, y2
and y3 occurring together.
After this step it keeps going till <eos> is reached.
Improvements that can be done in the above model for better accuracy
- One of the problems with the sequence to sequence model can be that it does not produce factual details accurately. For this a pointer generator network can be used. In pointer generator network, pgen probability to generate a word from the vocabulary V is calculated. The probability depends on the context vector (generated from attention) ht*, decoder hidden state st and decoder input xt. pgen is used as a switch to choose between generating a word from vocabulary or copying a word from the input sentence by using attention distribution scores.
where σ is sigmoid function and vectors wh∗ , ws , wx and scalar bptr are learnable parameters.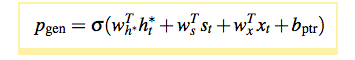
The advantage of using pointer generator network is that if a word w does not exist in the model’s vocabulary then Pvocab(w) = 0. Also if the word w is not present in the source document then it will have no attention. Therefore, this network has the ability to output OOV word.
- The model tends to repeat itself. For this, coverage can be used to keep a track of what has been summarized . A coverage vector ct is maintained, that is the sum of attention distributions over all previous decoder timesteps. The coverage mechanism represents the degree of attention/coverage the word has received from attention mechanism. This coverage vector can be used as an extra input to the attention mechanism so that it can be reminded about its previous decisions and thus preventing it from focusing on the same words.
- Sentence level attention can be used when the source document is very long. It means that we should find the most attentive sentences in the document along with calculating which words are more attentive in the document. Both word level and sentence level attention are used to compute the context vector that can be passed to the decoder.
Future Work
In the part 2 of this blog, you can find an implementation of the same.
Reference
- https://machinelearningmastery.com/encoder-decoder-deep-learning-models-text-summarization/
- Abigail See, Peter J. Liu, Christopher D. Manning : “Get To The Point: Summarization with Pointer-Generator Networks” https://arxiv.org/pdf/1704.04368.pdf
- Ramesh Nallapati, Bowen Zhou, Cicero dos Santos: “Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond”https://arxiv.org/pdf/1602.06023.pdf
- Alexander M. Rush, Sumit Chopra, Jason Weston: “A Neural Attention Model for Abstractive Sentence Summarization”https://arxiv.org/pdf/1509.00685.pdf
- https://guillaumegenthial.github.io/sequence-to-sequence.html
- https://hackernoon.com/beam-search-a-search-strategy-5d92fb7817f