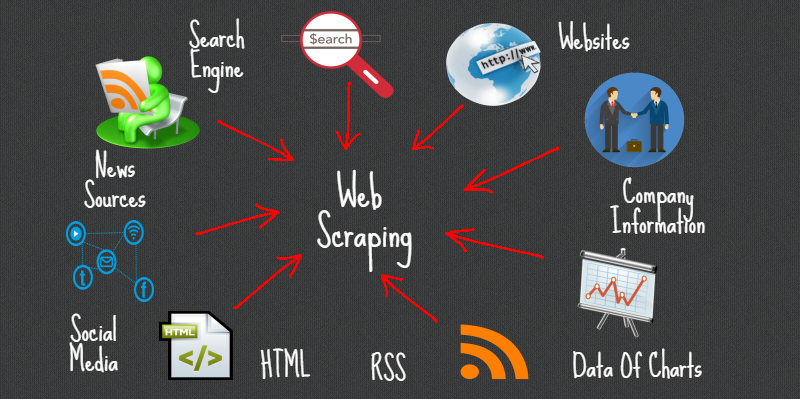
Web scraping made easy
Img Source: Gurutechnolabs, 2016
Web scraping is a way to extract data from one or more websites using a software. The data can later be saved to a local file or database and used for business by generating powerful insights or can come in handy to display 3rd party data on your site. Web data extraction therefore has become imperative for businesses in this competitive market.
Web scraping is especially useful when a website or a web based application does not provide a straightforward option such as exposing APIs to retrieve data. Web scraping is extremely powerful but it may also affect the website that is scraped if it is not implemented responsibly.
Let us discuss a few pointers to understand Web Scraping:
- Do not get confused with crawling
Web crawling is about viewing a page as a whole and indexing it. A web crawler follows links on a website and crawls through every page and every content present on the website or multiple websites. While web scraping focuses on specific content or specific pages of a given website (sometimes multiple websites). Scraped data is generally stored and later used for business or integration purposes.
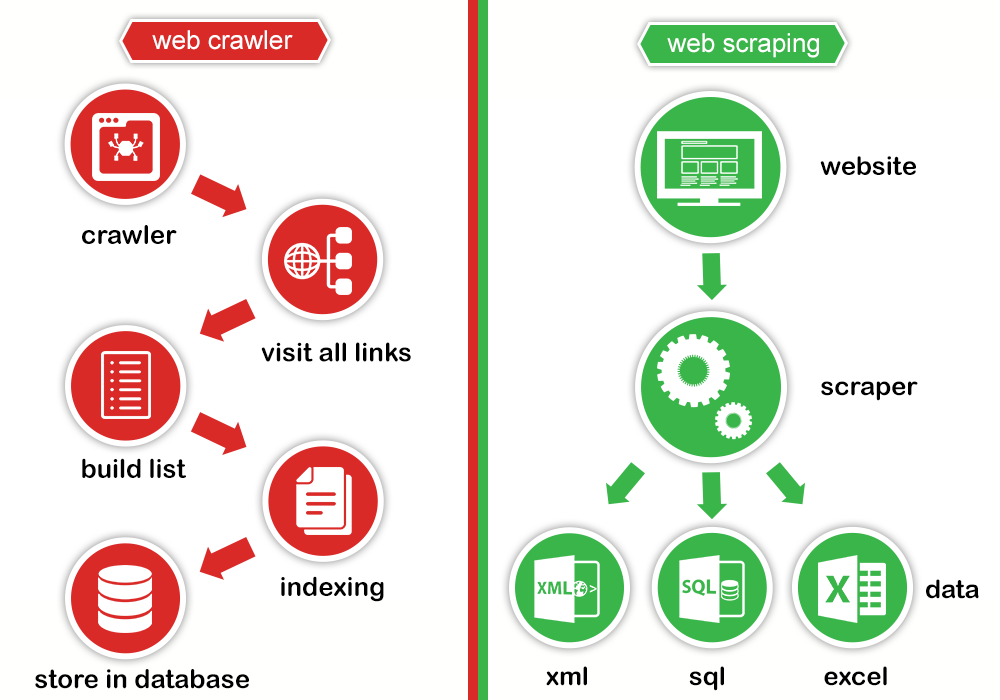
Img Source: Prowebscraping 2015
- Choose the website wisely
One should always go for websites where navigation from one page to another is easy and where website format does not change frequently. Websites with more static data and too many broken links are unreliable sources as crawling them could be maintenance workload in the long run.
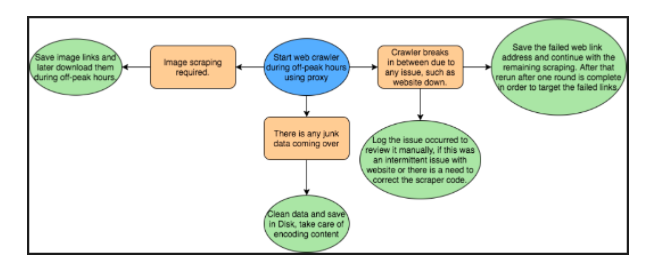
- Do not overload the website
To make sure that a website isn’t slowed down by requests due to high traffic by regular usage as well as web scraping bots, one should run web-scraper during off-peak hours and try to add some wait time between requests. The scraper should take all the information and store it to disk. In case the code breaks in between, one should take care to not download the whole content again and iterate over the failed ones only. If there is a requirement to scrap the same website, code for delta scraping can be written, where scraper will read and download only the latest content from the website. Processing of the data should be done later on after downloading content.
- User Proxies
It is always a good idea not scrape website with a single IP Address, because when you repeatedly send request to website, there is a chance that the remote web server might block your IP address in order to prevent their site from bot-attack. To overcome this situation, one should scrape websites with the help of proxy servers (anonymous scraping). This will minimize the risk of getting trapped and blacklisted by a website. You may also use a VPN instead of proxies to anonymously scrape websites.
- Image downloading
If there is a need to download images, try to do it post scraping. While scraping you can save the image URLs and later download it. This will reduce time and also the load on the website.
- Take care of unexpected surprises
One should also take care that the data being downloaded is not getting transformed into junk while saving. This could happen when the data encoding is different or some special characters are being used on the website. Also, if there is change in any specific section of the website, we should take care that the web scraper code does not break for rest of the sections. Also keep track of pages visited so that the scraper does not fall into infinite loop.
- Use an API
Do check if a site allows you to download data via API. This is a cleaner method of acquiring data as opposed to scraping.
By
Krati Parakh
Coviam Technologies
well explained