
BERT FOR SENTIMENT ANALYSIS OF CHATBOT CONVERSATIONS

BERT stands for Bidirectional Encoder Representations from Transformers. Before we get to it, first let’s understand what is sentiment analysis and why it is important in chatbot development.
Why is Sentiment Analysis crucial for Chatbots?
Chatbots have become an integral part of businesses to improve customer experience. The current focus in Industry is to build a better chatbot enriching human experience. Comprehension of customer reactions thus becomes a natural expectation., To achieve this, the chatbot needs to understand language, context and tone of the customer.
The opinion or sentiment expressed in a document or sentence can be binary (positive, negative) or fine-grained (positive, negative, strong-positive, strong-negative, neutral, mixed). Advanced analysis can go beyond polarity that includes classification of emotions (angry, sad, happy).
Enabling sentiment analysis on incoming messages does not only help change response as per user mood but also helps in advance analysis of services and breakdowns.
Not So Easy!
This analysis is not so easy as opinions can carry sarcasm, ambiguity and implicit negation. Some implicit negations like “When can I expect an answer” or a query like “How to cancel the order?” convolute the analysis as they are not directly negative but affect the business. This brings in the need to have a sentiment analyser trained on domain data.
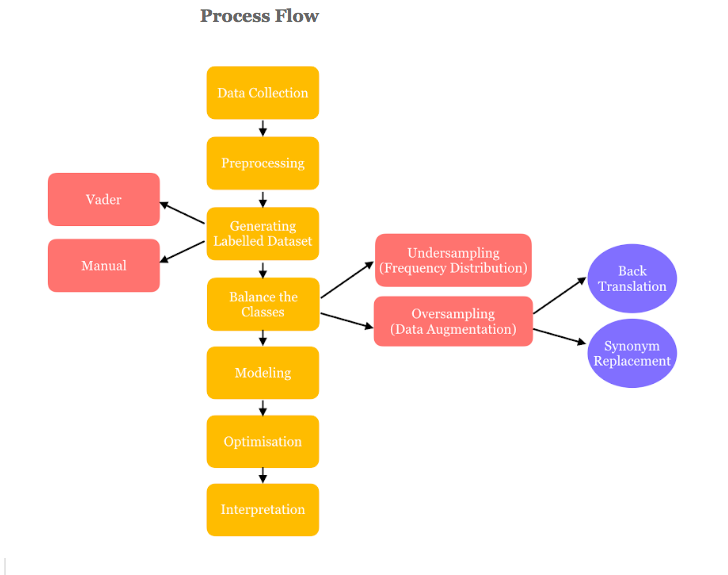
Data Collection
In case of chatbots that cater to multiple domains, variance in the data can be high.
Any ML or DL model needs sufficiently enough data for it to learn patterns, extracting features out of it.
The optimal number of data points for training is not a magic number.
Underfitting or Overfitting can lead to poor generalization.
Pre-processing
Clean the data to remove urls, emails, digits, special characters as they do not contribute in determining the sentiment but produce noise.
For a model to imitate how a human comprehends sentiment, It does not side with the generally followed practise of removing stop-words and lemmatization in NLP.
“How can I trust you” vs “I trust you”
“Do not make me angry” vs “I am not angry”
“You could be smarter” vs “You are smart”
Imagine these sentences reduce to the same thing whilst carrying completely different sentiments.
Labelling
When we talk about sentiments often we forget about a neutral class, which is nothing but lack of sentiment. It is okay to believe that the model should not classify it to Positive or Negative on the basis of confidence scores.
But keeping a separate Neutral class helps the model to clearly have a distinction between the two classes and improves accuracy.
Labelling the dataset is one of the most crucial steps as it drives the learning.
Rule Based Natural Language Processing Systems like VADER can be used for first level sentiment tagging to make Human review for the next stage easier.
Balance the Dataset
Learning on Imbalanced dataset tend to favor the majority class which may lead to misleading accuracies. This is particularly problematic when we are interested in the correct classification of a minority class.
Most of the chatbots today are for customer support, hence messages are highly variant queries that carry no sentiment at all.
Undersample the Neutral samples (on the basis of frequency distribution) and oversample the others to balance the dataset.
Oversample the minority classes using Data Augmentation techniques. To improve generalization, Data Augmentation is a well known strategy. Augmenting meaningful Positive and Negative samples using Back Translation with multiple languages and synonym replacement for the minority classes helps reduce manual labeling of more texts by generating new similar texts, and increases the accuracy significantly.
Modeling
To learn a good representation of the sentence, Keras trainable embeddings along with models like CNN and LSTMs can be used.
Tokenizers like sentencepiece and wordpiece can handle misspelled words.
Optimized CNN networks with embedding_dimension: 300, filters: [32, 64], kernels: [2, 3, 5], kernel_initialization: ‘he_uniform’, pooling strategy: (average and max on concatenated CNN layers) yield accuracy as high as 92%. This network could outperform Bidirectional LSTMs for the task.
Despite the high accuracy, both fail to generalize well and handle negation.
A good sentence Representation
Using pre-trained embeddings like Glove and Word2Vec didn’t help in boosting the performance as they are not contextual. A word can carry different meanings in different context. Like “block” with reference to “Block D” vs “The account is blocked” can mean two very different things.
Contextual Embeddings are thus important to perceive the correct meaning, and training those requires huge amount of data.
For any Business, the availability of data and resources to model it are the major concerns. It is not practical to continually feed the model with more and more data. This requirement opened the gates for Transfer Learning.
Unleash the power of BERT
(Bidirectional Encoder Representations from Transformers)
Bert is a Contextual model. Instead of generating a single word embedding representation for each word in the vocabulary. It generates the representation of each word that is based on the other words in the sentence.
Applying the bidirectional training of Transformer, a popular attention model, to masked language modelling can have a deeper sense of language context and flow than single-direction language models.
It is pre-trained on massive wikipedia and book corpus datasets.
BERT only uses the Encoder of the transformer model. A total of N encoder blocks are stacked together to generate the Encoder’s output.
A specific block is in charge of finding and encoding patterns or relationships between the input representations. BERT uses 12 separate attention mechanisms for each layer. Each token can focus on 12 distinct aspects of other tokens. Each head can focus on a different kind of constituent combinations.
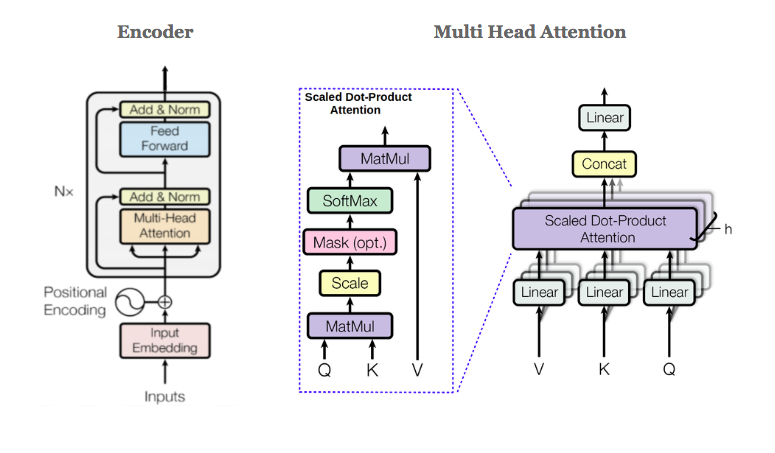
BERT is a pretrained model that expects input data in a specific format. Special tokens to mark the beginning ([CLS]) and separation/end of sentences ([SEP]).
BERT passes each input token through a Token Embedding layer so that each token is transformed into a vector representation, Segment Embedding Layer (to distinguish different sentences) and Position Embedding Layer (to show token position within the sequence).
BERT tokenizer has a WordPiece model, it greedily creates a fixed-size vocabulary. Its vocab size limits to 30,000. It includes words, subwords (front and back) and characters.
The detailed working of a Transformer model and Bert by Google.
Fine Tuning Bert
Bert can be used as a feature extractor, where meaningful sentence representation can be constructed by concatenating the output of the last few layers or averaging out the output of the last layer of the pre-trained model.
Fine tuning with respect to a particular task is very important as BERT was pre-trained for next word and next sentence prediction.
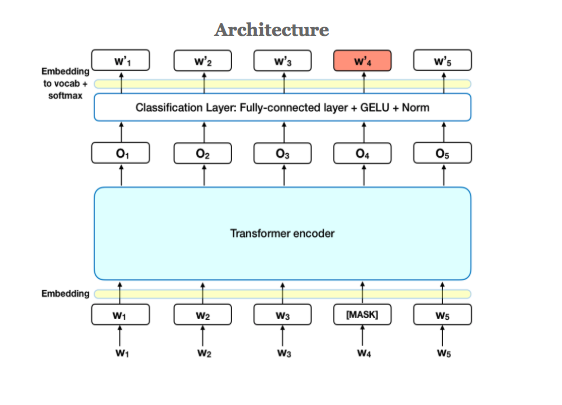
Sentiment analysis with BERT can be done by adding a classification layer on top of the Transformer output for the [CLS] token.
The [CLS] token representation becomes a meaningful sentence representation if the model has been fine-tuned, where the last hidden layer of this token is used as the “sentence vector” for sequence classification.
Pretrained Model:
bert-base-uncased (12-layer, 768-hidden, 12-heads, 110M parameters)
Processor:
Custom or Cola Processor with Label_list: [“Neutral”, “Negative”, “Positive”]
Dataset: ChatBot conversations
Fine-tuning parameters:
max_seq_length= 30
batch_size= 32
learning_rate=2e-5
num_train_epochs=4.0
warmup_proportion=0.1
(The learning rate increases linearly over the warm-up period.
If the target learning rate is p and the warm-up period is n, then the first batch iteration uses 1*p/n for its learning rate; the second uses 2*p/n , and so on until we hit the nominal rate at iteration n)
Results
eval_accuracy = 0.93949044
eval_loss = 0.22454698
Test_accuracy = 0.9247
Experiments with the output of the last encoder:
[CLS] token representation: eval_acc 0.939
Global Max Pooling: eval_acc 0.9458
Global Average Pooling: eval_acc 0.9522
This model generalizes well on un-seen cases and can capture negation cases or implicit negation even with less training data.
Interpretability and Explainability
Deep Learning models are thought of as a black box, which is unlikely to hold true anymore. False cases can be interpreted and explained by looking at the attention on each token that lead to a particular prediction.
Much work has been done on the pre-trained models for Next Sentence Prediction like BertViz in pytorch.
In Sentiment Analysis, similar analysis on self attention layers can be done.
Algorithm:
- Take the attention weights from the last multi-head attention layer assigned to the [CLS] token.
- Average each token across multiple heads
- Normalise across tokens
Visualization
It is hard for a human to perceive large n dimensional arrays.
However, all of it is not so formidable when put up into a visualization.
One can do a Synopsis with the visualization of intensity or attention of each token in a sentence.
Examples

References
[1] Attention Is All You Need; Vaswani et al., 2017.
[2] Pre-training of Deep Bidirectional Transformers for Language Understanding; Devlin et al., 2018.
[3] XLNet: Generalized Autoregressive Pretraining for Language Understanding; Zhilin Yang., 2019
[4] A Robustly Optimized Pretraining Approach; Yinhan Liu., 2019
[5] ERNIE: Enhanced Language Representation with Informative Entities; Zhengyan Zhang., 2019
[6] A tool for visualizing multi-head self-attention in the model; Jesse Vig., 2019
[7] Bert as Service; Hanxio
Also, you can read our blog on React JS