Get a handle on deep learning with “Attention”
At Coviam, being part of the deep learning team, we try to solve use cases that our partners and platforms face in enabling more machine learning intelligence for automation. Our focus ranges from text-based NLP (Natural Language Processing) to NLU (Understanding) to NLG (generation) to voice and image recognition. Our work focuses on the world of algorithms and how do we train machines to perform like humans. It has been an exciting journey so far and the area of NLP is just opening up to the realm of possibility of how technology can enable humans to be more productive while machines can do rote or tasks that can be automated.
In our discovery and journey along the pathways of using this approach and technology across business problems, we use various techniques and algorithms. Today we will talk of an application of neural networks and the applicability of a technique called “Attention”
What is Attention in Neural Networks?
Attention is a concept in neural networks that is used to understand sequences like a sequence of words, actions, video, voice etc.
A human brain implements attention in many situations so that the person can focus on the important information rather than all the information available.
For example, when humans read, they fixate on some words and skip others. Consider a small passage, “Teachers, like other professionals, may have to continue their education after they qualify, a process known as continuing professional development. Teachers may use a lesson plan to facilitate student learning, providing a course of study which is called the curriculum”
In order to answer the question, “What is the course of study called?”, a human will focus on the words “course”, “study”, “name given to the course”. Therefore, these parts of the story need attention. The rest of the passage is not very relevant with respect to the question.
Understanding Attention in detail
Deep Learning for Language Modeling with Attention
A recurrent neural network(RNN) is a class of neural networks where connections between nodes form a directed graph along a sequence. RNNs are called recurrent because they perform the same task for every element in the sequence, with the output being dependent on the previous computations. These are used in situations where the output is dependent on the input at every time step, for example generating text.
But there is a disadvantage with RNNs which is known as the problem of long-term dependencies. For example, consider a language model trying to predict the next words based on the previous words , suppose in the sentence “Trees are green in color” the last word is to be predicted, then here the context of all the words before the last word is needed, where the gap between the relevant information and the information to be predicted is less, therefore RNNs can be used here. But for cases like “I grew up in France. I like spending time with my parents. ……..I speak fluent____”, the last word in this is a language which can be understood by the context of “speak fluent” but for knowing which language we need to know the context of “France”, which is not possible in RNNs. Therefore, as the gap grows, RNNs are not able to persist the information.
LSTMs (Long Short Term Memory) is capable of handling long-term dependencies. Remembering information for long periods of time is their default behaviour. But since all information is not important for the LSTM to remember and process, therefore we need attention so that only relevant information can be processed by the LSTM.
Sequence to Sequence Models
A sequence to sequence modelling problem is the one where the input, as well as the output, are sequences. For example Machine Translation, Question Answering etc. A typical sequence to sequence model has two parts an encoder and decoder. Both are two different neural networks combined together to form a giant network.
The task of the encoder is to understand the input and convert it from symbolic space into numeric space by encoding. The decoder takes the encoded representation as input and generates a sequence of output by converting it from numeric space into symbolic space that can be understood by humans.
The encoder encodes the input sequence while the decoder produces the output sequence.
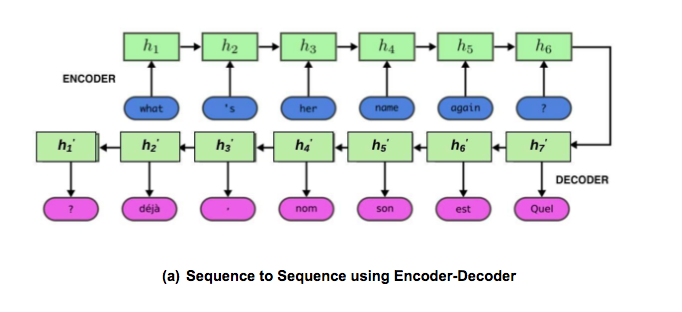
In figure (a), the input sequence is “what”, “‘s”, “her”,”name”,”again” and ”?”. Since the machines cannot understand natural language, therefore, this input is first converted from symbolic space into mathematical representation called as vectors that can be processed by machines. This process is called as embedding. Therefore, the input to the encoder will be the vector representations of these words which are called as input vectors. Then, LSTM is run over this input. The output produced by the LSTM, called as hidden states, are not the final output but considered as an input to the decoder.
The last hidden state output of the LSTM is called as the encoder representation. The hidden state representations are h1, h2, h3, h4, h5 and h6.
In the decoder the input is encoder representation from the encoder that captures the meaning of the input sequence so we will use it to generate the output sequence. The decoder LSTM produces a hidden state h1’, h2’, h3’ and so on. This hidden state is a mathematical representation, it is converted into symbolic space for humans to understand the output of the decoder.
Hope you got a fair idea on how an Encoder-Decoder works.
Encoder-Decoder with attention
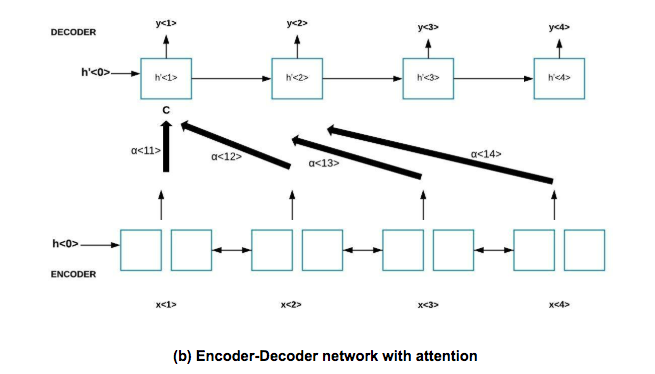
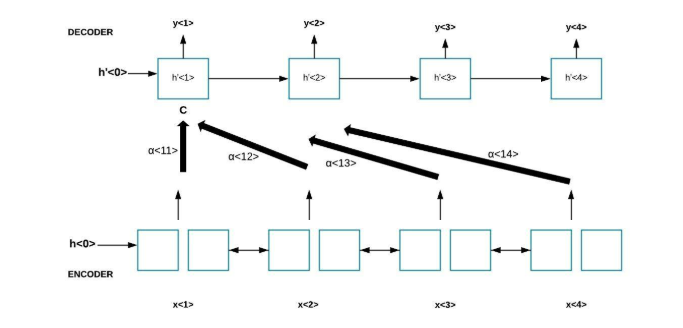
In Figure (b), we can see an encoder-decoder architecture. Consider an input sentence that is fed into the encoder. Here, x<1>, x<2>, x<3> and x<4> are the input vectors. The encoder is a LSTM that is used on the input sentence. The hidden state vectors are formed after the forward and backward propagation in the LSTM. The decoder is also a LSTM that takes as input a state vector s to generate the output. The state vector uses context vector C and the last hidden state from the encoder. The context vector C depends on the attention parameters i.e α<1,1>, α<1,2> and so on. The attention parameters tell how much attention is given to each input vector i.e each word in the input.
It tells how much does the context C depend on each input vector. Context is calculated as the sum of these input vectors that is weighted by the attention weights (α<>).
α<1,t> =1 (sum of attention weights = 1 and t means every time step)
c<1> = Σ α<1,t’> h<t’> where α<t, t> is the attention y<t> shall pay to h<t’> which is the encoded input vector at t’.
The output of decoder y<1> depends on the hidden state vector h’<1> and c<1> Similarly, for generating the second output, context vector c<2> is used with hidden state vector h’<2> and previous output i.e y<1>.
To compute α<t, t’>,

The figure (c) shows formula to compute attention weights α<t, t’> and it is a softmax function. The softmax function is an activation function that squashes the outputs of each unit to be between 0 and 1 as for a fixed value of t these attention weights sum to 1. e<t,t’> is the score for the encoder hidden state h<t’> and decoder hidden state h<t>’. Softmax is used to normalise all scores that generates probability distribution conditioned on target state t.
Difference between Soft attention and Hard attention
A range of attention based neural networks has been recently developed in domains like NLP and computer vision. Attention-based neural networks either use soft attention or hard attention. In soft attention instead of using the entire text as input to the LSTM, we input weighted text features to the LSTM. Therefore, soft attention gives less weight to the irrelevant text and more weight to the relevant text.
Whereas in hard attention, each part of the text is either used to make the context vector or is discarded i.e it selects only the parts of the input to focus on.
In NLP, soft attention can mitigate the difficulty of compressing long sequences into fixed-dimensional vectors, with applications in machine translation and question answering whereas in computer vision both types of attention can be used for selecting regions in an image.
Future work
Attention mechanism can be applied to image captions. The task is to look at a picture and write the caption for that picture. We will post an implementation of image captioning using attention in a future blog.
References
- Attention is All You Need: https://arxiv.org/pdf/1706.03762.pdf
- Sequence Models – By Andrew Ng
- https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129
- https://towardsdatascience.com/memory-attention-sequences-37456d271992
- https://guillaumegenthial.github.io/sequence-to-sequence.html
Rashika
Deep learning team
Coviam Technologies
Also published on Medium.