Service Discovery in a Micro-service Architecture
Microservices have gained a lot of tech community attention lately, Mainly because – how easy and powerful software architecture can be built using microservice. They are also rapidly heading towards the peak of inflated expectations on the Gartner Hype cycle. And at the same time, there are skeptics in the software community who dismiss microservices as nothing new. Well, that’s because the fundamental behind building a microservice architecture is de-coupling and cohesiveness. At-least that’s what I consider as a fundamental. And building decoupled and highly cohesive systems are nothing new.
Naysayers claim that the idea is just a rebranding of SOA. However, despite both the hype and the skepticism, the Microservices Architecture pattern has significant benefits – especially when it comes to enabling the agile development and delivery of complex enterprise applications.
This blog is not really about microservice, because I assume that either you have already built it or working on microservice architecture. This blog is about Service Discovery in a Micro-service Architecture. Now, as I described above the fundamentals of microservice architecture, there are fundamental pillars as well. One of those is a Service Discovery.
Before going deep into Service Discovery, I would tell you that if you say you have a micro-service architecture and you don’t have Service Discovery, and still using property files or relational database for such thing, then you need to think again and might want to tell your architect to take Distributed System 101 classes because I am very sure he doesn’t know or understand it. No offense though.
Coming back to business, I was talking about Service Discovery. Let’s imagine that you are writing some code that invokes a service that has a REST API. In order to make a request, your code needs to know the network location (IP address and port) of a service instance. In a traditional application running on physical hardware, the network locations of service instances are relatively static. For example, your code can read the network locations from a configuration file that is occasionally updated. But in a modern, cloud‑based microservices application, however, this is a much more difficult problem to solve as shown in the following diagram.
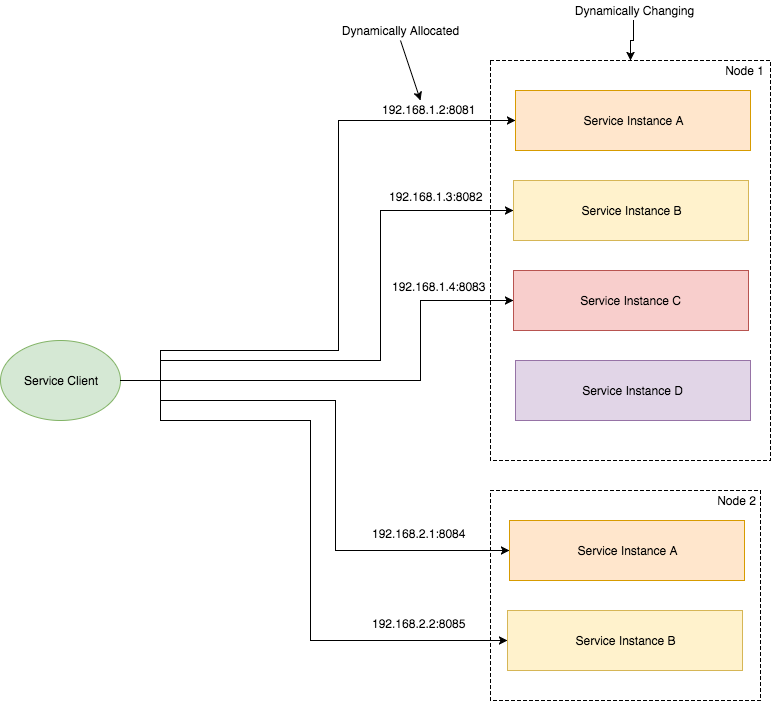
Service instances have dynamically assigned network locations. Moreover, the set of service instances changes dynamically because of autoscaling, failures, and upgrades. Consequently, your client code needs to use a more elaborate service discovery mechanism.
From above picture, you can easily understand that our client code needs to first discover service instance and then if found many, load balance among them. Which eventually lead to having following in place to do that –
- Service Registry
- Client-side Discovery
- Server-side Discovery
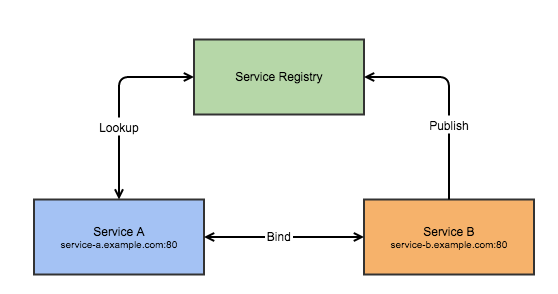
Service Registry
The heart of any service discovery mechanism is service registry. It is a database of services, their instances, and their locations. Service instances are registered with the service registry on startup and deregistered on shutdown. A client of the service query the service registry to find the available instances of a service. A service registry might also invoke a service instance’s health check API to verify that it is able to handle requests.
A service registry needs to be highly available and up to date. Clients can cache network locations obtained from the service registry. However, that information eventually becomes out of date and clients become unable to discover service instances. Consequently, a service registry consists of a cluster of servers that use a replication protocol to maintain consistency.
There are many service discovery software exists today out of which Netflix Eureka, Consul and etcd are the best from my view point. Netflix Eureka is an excellent example of a service registry. It provides a REST API for registering and querying service instances. A service instance registers its network location using a POST request. Every 30 seconds it must refresh its registration using a PUT request. A registration is removed by either using an HTTP DELETE request or by the instance registration timing out. As you might expect, a client can retrieve the registered service instances by using an HTTP GET request. You can run one or more Eureka servers in different availability zones for achieving high availability.
Other examples of service registries include:
- etcd – A highly available, distributed, consistent, key‑value store that is used for shared configuration and service discovery. Two notable projects that use etcd are Kubernetes and Cloud Foundry.
- consul – A tool for discovering and configuring services. It provides an API that allows clients to register and discover services. Consul can perform health checks to determine service availability.
- Apache Zookeeper – A widely used, high‑performance coordination service for distributed applications. Apache Zookeeper was originally a subproject of Hadoop but is now a top‑level project.
If you are on container orchestrator platforms like kubernetes, marathon, docker swarm or aws ecs, you might not need service discovery explicitly since they are part of the orchestrator itself.
Service Registration Options
As discussed earlier, service instances must be registered with and deregistered from the service registry. There are a couple of ways to achieve that. One option is for service instances to register and deregister themselves on startup and shutdown respectively. It is called self‑registration pattern. Another option is to use third party component to manage registration and de-registration of service instances. It is called the third‑party registration pattern. We will see both the patterns in more detail in coming articles.
Client-side Discovery
In Client-side discovery, the client is responsible for determining the network locations of available service instances and load balancing requests across them. The client queries a service registry and then uses a load‑balancing algorithm to select one of the available service instances and makes a request. It also makes sure that client is in a healthy state before making a request.
The following diagram shows the structure of this pattern –
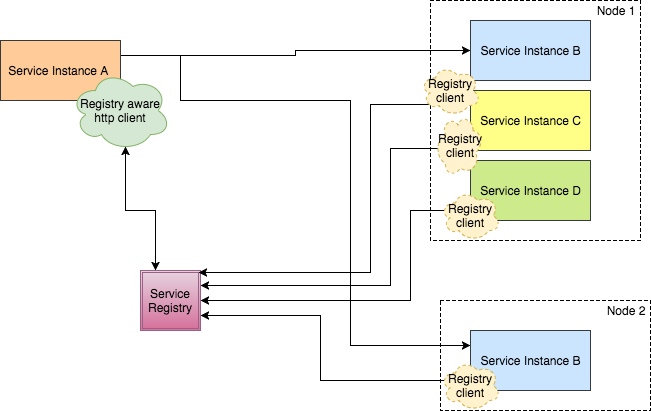
As discussed earlier, the network location of a service instance is registered with the service registry when it starts up. It is removed from the service registry when the instance terminates. The service instance’s registration is typically refreshed periodically using a heartbeat mechanism.
There are a variety of benefits and drawbacks associated with client-side discovery. This pattern is relatively straightforward and, except for the service registry, there are no other moving parts. Also, since the client knows about the available services instances, it can make intelligent, application‑specific load‑balancing decisions such as using hashing consistently. One significant drawback of this pattern is that it couples the client with the service registry. You must implement client‑side service discovery logic for each programming language and framework used by your service clients.
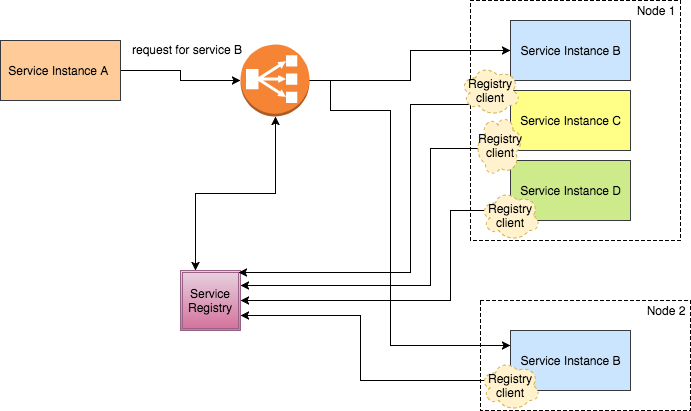
Server-side Discovery
In Server-side Discovery, the client makes a request to a service instance via a load balancer (or a proxy server). The load balancer queries the service registry and routes each request to an available service instance. As with client‑side discovery, service instances are registered and deregistered with the service registry.
Server-side discovery is relatively easy to manage since the entire discovery configuration goes at load balancer instead of all service clients. This eliminates the need to implement discovery logic for each programming language and framework used by your service clients. Also, as mentioned above, some deployment environments (Kubernetes, Marathon AWS etc.) provide this functionality for free. This pattern also has some drawbacks, however. Unless the load balancer is provided by the deployment environment, it is yet another highly available system component that you need to set up and manage.
Conclusion
Service Discovery is an essential architectural pattern to be implemented with microservice architecture to allow it to easily scale and distributed across a cluster of nodes. The key piece in implementing a service discovery is a highly available Service Registry which acts as a truth store from where all service instances discover each other. Service instances can either implement client-side or rely upon server side discovery for making a request. Netflix Eureka, Consul, etcd, zookeeper are some of the popular Service Registries available today. Orchestrator frameworks like Kubernetes, Marathon, AWS ECS etc provides Service Discovery out of the box.
In future blog posts, we’ll continue to dive into other aspects of microservices and service discovery. We will also show you a working example of implementing a Service Discovery using Docker, Consul and nginx that we use here at Peoplehum – an employee engagement solution by Coviam.